

Lesezeit: 5 Minuten
Mit DynamoDB starten - erste Einblicke in die AWS Key-Value Datenbank - Teil 1
In der Cloud-dominierten Landschaft von heute nimmt Amazon Web Services (AWS) eine herausragende Rolle ein. Neben traditionellen SQL-Datenbanken gewinnt auch die NoSQL-Datenbank DynamoDB zunehmend an Bedeutung. Als serverloser Dienst von AWS bietet sie Flexibilität und Skalierbarkeit für vielfältige Datenanforderungen. DynamoDB ist exklusiv im Amazon-Ökosystem verfügbar und als spezialisierte Lösung einzigartig positioniert.
Dieser Artikel zielt darauf ab, ein Grundverständnis für DynamoDB zu vermitteln und die wichtigsten Konzepte zu erläutern. Ziel ist es, Szenarien zu identifizieren, in denen der Einsatz von DynamoDB sinnvoll ist. Wir werden uns eingehend mit den Grundlagen dieser NoSQL-Datenbank befassen, einschließlich Kernkomponenten, Schlüsselkonzepten wie Primary Keys, Partition Keys und Sort Keys, dem Auslesen von Entitäten und der Verwaltung von Relationen.
Grundlegende Konzepte
Kernkomponenten
Als Erstes betrachten wir die Kernkomponenten von DynamoDB, die für das Verständnis und die effektive Nutzung dieser Datenbankplattform essenziell sind.
- Speicherung von Daten als Elemente: DynamoDB speichert Daten in Form von "Elementen". Jedes Element besteht aus Attributen, ohne dass eine starre Schemastruktur vorgegeben ist. Dies ermöglicht die Speicherung verschiedenartiger Elemente, jeweils mit ihren individuellen Attributen.
- Organisation in Tabellen: Die in DynamoDB gespeicherten Elemente werden in Tabellen abgelegt. Ein charakteristisches Merkmal von DynamoDB ist die Fähigkeit, Elemente mit unterschiedlichsten Schemata in einer einzigen Tabelle zu organisieren.
- Key-Value-Speicheransatz: DynamoDB verwendet für die Speicherung von Daten einen eindeutigen Schlüssel. Dieser Key-Value-Ansatz ist charakteristisch für die Datenbank und vereinfacht den schnellen Zugriff auf spezifische Datenelemente.
- Effiziente Partitionierung: Die Datenbank verwendet eine Hashfunktion, um Elemente auf verschiedene Partitionen zu verteilen. Diese Partitionierung trägt dazu bei, Daten effizient zu organisieren und zu verwalten, was wiederum die Leistung und Skalierbarkeit von DynamoDB verbessert.
- Automatisierte Verwaltung der Partitionen: Ein weiterer Vorteil von DynamoDB ist die automatische Verwaltung der Partitionen. Dies entlastet die Nutzer von administrativen Aufgaben und ermöglicht es ihnen, sich auf andere wichtige Aspekte der Datenbanknutzung zu konzentrieren.
Keys
Die Schlüssel spielen eine zentrale Rolle in der Architektur von DynamoDB. Sie sind nicht nur entscheidend für die Identifikation und den Zugriff auf einzelne Elemente in einer Tabelle, sondern auch für die effiziente Verteilung der Daten über die verschiedenen Partitionen der Datenbank. Eine durchdachte Wahl der Schlüssel ist daher essenziell, um die Leistungsfähigkeit von DynamoDB voll auszuschöpfen.
Der Primary Key ist das fundamentale Element zur Identifikation eines Elements in einer Tabelle. Er besteht aus Attributen des Elements und muss für jedes Element einzigartig sein, sodass er nicht mehrfach vergeben werden kann. Als Attributkombination kann der Primary Key entweder ausschließlich aus dem Partition Key bestehen, der ein spezifisches Attribut des Elements ist, oder aus einer Kombination des Partition Keys und eines weiteren Attributs, dem Sort Key. Diese beiden Schlüsselattribute definieren zusammen die Einzigartigkeit jedes Elements in der Tabelle. Diese beiden Schlüsselattribute definieren zusammen die Einzigartigkeit jedes Elements in der Tabelle.
- Partition Key: Der Partition Key ist von zentraler Bedeutung für die interne Datenverwaltung in DynamoDB. DynamoDB nutzt den Wert des Partition Keys, um eine interne Hash-Funktion zu speisen. Das Ergebnis dieser Hash-Funktion bestimmt, in welcher Partition das jeweilige Element gespeichert wird. Wenn nur der Partition Key verwendet wird, muss jedes Element in der Tabelle einen einzigartigen Partition Key besitzen.
- Sort Key: Die Integration eines Sort Keys eröffnet zusätzliche Möglichkeiten in der Datenstrukturierung. In diesem Fall muss die Kombination aus Partition Key und Sort Key einzigartig sein. Dies erlaubt, dass sich der Partition Key wiederholen darf, solange der Sort Key in der Kombination einzigartig bleibt. Diese Konfiguration ermöglicht es, dass Elemente mit dem gleichen Partition Key in derselben Partition gespeichert werden, was eine effiziente Abfrage und Organisation der Daten erlaubt.
Beispiel:

Die dargestellte DynamoDB-Tabelle zeigt die Verknüpfung von Studenten und Professoren mit den Seminaren, die sie besuchen oder halten. Jede Zeile der Tabelle repräsentiert ein einzigartiges Objekt, wobei der Partitionsschlüssel (PK) den Namen des Studenten oder Professors angibt und der Sortierschlüssel (SK) das spezifische Seminar angibt.
Lesen von Elementen aus einer Tabelle
Das Abrufen von Daten in DynamoDB unterscheidet sich grundlegend von traditionellen SQL-basierten Datenbanken. Anstelle von komplexen Abfragen basiert der Datenzugriff hier auf vordefinierten Schlüsseln:
- Abfrage der Elemente mittels Keys: Jedes Element in der Tabelle ist eindeutig über seinen Primary Key identifizierbar. Dies ermöglicht schnelle und direkte Abfragen einzelner Elemente. Zusätzlich ist der Abruf von Elementen über Secondary Indexes möglich, was später noch genauer erläutert wird.
- Abfragemethoden:
- Exakter Partition Key: Direkte Abfrage eines Elements über seinen spezifischen Partition Key.
- Kombination aus Partition Key und Sort Key: Ermöglicht präzise Abfragen durch die Kombination beider Schlüssel.
- Partition Key mit Bereichsabfragen auf den Sort Key: 'Begins with'- oder 'In between'-Abfragen erweitern die Möglichkeiten, indem sie eine Suche basierend auf dem Partition Key und einem Bereich oder Anfangswert des Sort Keys erlauben.
Diese Methoden gelten sowohl für den Primary Key als auch für die in DynamoDB verfügbaren Secondary Indexes.
Für den Abruf und die Abfrage von Daten stellt DynamoDB zwei Hauptwerkzeuge zur Verfügung:
- Tools für den Datenzugriff:
- DynamoDB-API: Eine API, die eine Vielzahl an Operationen zum Lesen, Schreiben und Aktualisieren von Daten bereitstellt.
- PartiQL: Eine SQL-ähnliche Abfragesprache für DynamoDB; ideal für Nutzer, die bereits mit SQL vertraut sind.
Beispiel:

Diese DynamoDB-Tabelle dokumentiert die akademischen Aktivitäten von Professoren, darunter die Durchführung von Seminaren und die Veröffentlichung von Forschungsartikeln.
Wenn wir alle Aktivitäten des Professors "Prof. Dr. Clara Codekraft" abfragen wollen, würden wir eine Abfrage stellen, die ausschließlich auf dem Partition Key basiert:

Diese Abfrage würde alle Zeilen zurückgeben, in denen der Partition Key gleich "Professor#Prof. Dr. Clara Codekraft" ist, unabhängig davon, was der Sort Key ist.
Um spezifisch das Seminar "Vernetzte Systeme verstehen", das von "Prof. Dr. Clara Codekraft" gehalten wird, abzufragen, würden wir eine Abfrage formulieren, die sowohl den Partition Key als auch den Sort Key verwendet.

Diese Abfrage liefert nur die Zeile, in der der Partition Key "Professor#Prof. Dr. Clara Codekraft" und der Sort Key "Seminar#Vernetzte Systeme verstehen" ist.
Secondary Indexes
In DynamoDB ist die Erstellung von einem oder mehreren secondary Indexes möglich, um die Flexibilität bei der Datenabfrage zu steigern. Normalerweise erfolgt der Zugriff auf Daten in DynamoDB ausschließlich über den Primary Key. Secondary Indexes erweitern jedoch diese Möglichkeit, indem sie zusätzliche Attribute für den Datenabruf zur Verfügung stellen. Dadurch wird eine deutlich größere Flexibilität beim Abfragen der Daten erreicht.
DynamoDB unterstützt zwei Arten von secondary Indexes, die jeweils unterschiedliche Anwendungsfälle und Vorteile bieten:
- Global secondary Index: Dieser Index-Typ ermöglicht es, einen völlig unabhängigen Partitionsschlüssel und Sortierschlüssel zu definieren, die sich von denen in der Tabelle unterscheiden können. Dies bietet eine hohe Flexibilität und erlaubt es, Daten auf Basis unterschiedlicher Kriterien zu organisieren und abzurufen.
- Local secondary Index: Ein local secondary Index teilt denselben Partitionsschlüssel wie die zugrundeliegende Tabelle, verwendet jedoch einen anderen Sortierschlüssel. Diese Index-Art ist besonders nützlich, um Abfragen innerhalb einer bestimmten Partition zu optimieren, indem sie alternative Sortiermöglichkeiten bietet.
Beim Anlegen eines Indexes in DynamoDB ist es wichtig, die Projektion von Attributen zu definieren – also zu bestimmen, welche Attribute aus der Basistabelle in den Index übernommen werden sollen. Standardmäßig werden mindestens die Schlüsselattribute der Basistabelle in den Index projiziert. Das bedeutet, dass der Partitionsschlüssel und, falls vorhanden, der Sortierschlüssel automatisch in den secondary Index aufgenommen werden. Abhängig von den Anforderungen Ihrer Anwendung können Sie zusätzliche Attribute für die Projektion auswählen, um spezifische Abfragebedürfnisse zu unterstützen und den Zugriff auf relevante Daten im Kontext des Indexes zu optimieren.
Beispiel:
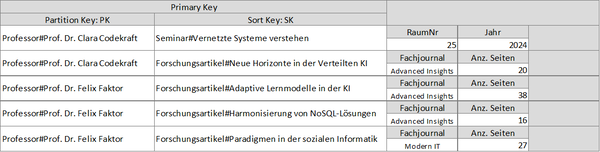
Um spezifische Abfragen nach dem veröffentlichten Fachjournal zu ermöglichen, kann in DynamoDB ein secondary Index eingerichtet werden, der als "FachjournalIndex" bezeichnet wird. Dieser Index strukturiert die Daten so, dass die Forschungsartikel effizient nach dem Namen des Journals und dem verantwortlichen Professor kategorisiert werden können.
Index-Struktur:
- Name des Indexes: FachjournalIndex
- Partition Key: Fachjournal
- Sort Key: PK (Der originale Partition Key der Haupttabelle)
- Projiziertes Attribut: SK (Der originale Sort Key der Haupttabelle)
Wenn wir die im "Advanced Insights" veröffentlichten Artikel abrufen möchten, könnte die Abfrage wie folgt aussehen:

Dies würde eine Ergebnisliste im JSON-Format liefern, die alle Artikel aus diesem Journal enthält, mit ihren Titeln und den Autoren:

Möchte man ausschließlich die Artikel von "Prof. Dr. Felix Faktor" aus dem Journal "Advanced Insights" einsehen, würde man die Abfrage wie folgt anpassen:

Die Antwort würde in diesem Fall so aussehen:

Fortsetzung folgt...
Wir haben heute umfassende Einblicke in die Grundlagen von DynamoDB gewonnen, einschließlich der Datenstrukturierung, Speicherung und Abfrage in dieser leistungsstarken NoSQL-Datenbank. Besonderes Augenmerk wurde auf Keys und secondary Indexes gelegt, die eine effiziente Datenorganisation und Abfrage ermöglichen. Im nächsten Blogartikel werden wir uns in die Modellierung von Beziehungen innerhalb von DynamoDB vertiefen.

